# 编译原理
《编译系统透视:图解编译原理》读书笔记
# C程序的运行式结构
C程序运行的核心是函数的执行和调用,它构成了整个C程序运行时结构的基础框架。这一运行过程主要是在程序指令的驱动以及数据压栈、清栈的支持下实现的。
以下面的程序为例:
int fun(int a, int b);
int m = 10;
int main() {
int i = 4;
int j = 5;
m = fun(i, j);
return 0;
}
int fun(int a,int b) {
int c=0;
c=a+b;
return c;
}
2
3
4
5
6
7
8
9
10
11
12
13
# 程序加载时的内存概况
运行时,在内存中,共有代码区、静态数据区和动态数据区三个区域。
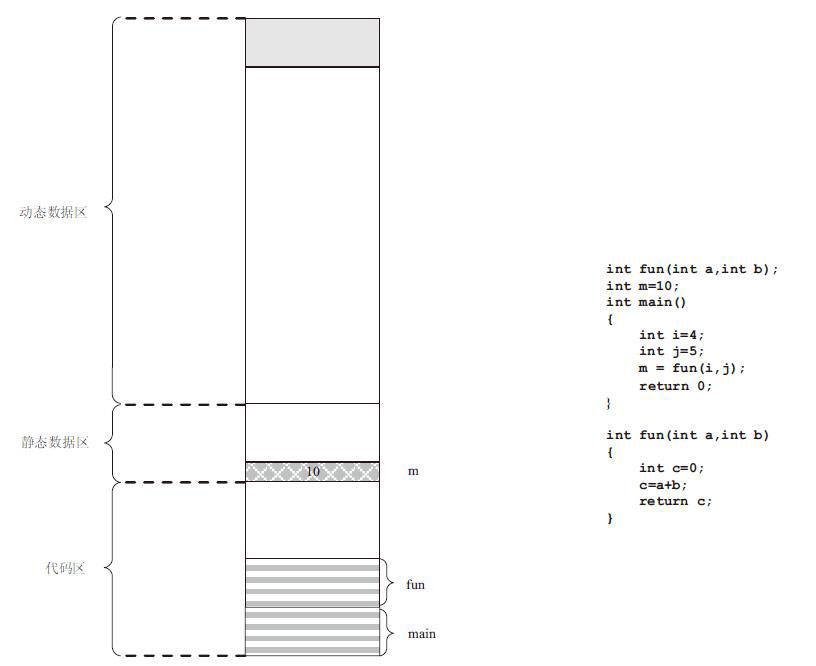
其中,代码区装载了程序所对应的机器指令;全局变量m的数值装载在静态数据区中;动态数据区加载程序运行过程中产生的数据。
程序执行的本质就是代码区的指令不断执行,驱使动态数据区和静态数据区产生数据变化。
CPU中有三个寄存器,分别是eip、ebp和esp。
eip永远指向代码区将要执行的下一条指令,它的管控方式有两种,一种是“顺序执行”,即程序执行完一条指令后自动指向下一条执行;另一种是跳转,也就是执行完一条跳转指令后跳转到指定的位置。
ebp和esp用来管控栈空间,ebp指向栈底,esp指向栈顶。在代码区中,函数调用、返回和执行伴随着不断压栈和清栈,栈中数据存储和释放的原则是后进先出。
eip指向main函数的第一条指令,此时程序还没有运行,栈空间里还没有数据,ebp和esp指向的位置是程序加载时内核设置的。
# 程序运行过程中的内存变化
程序开始执行main函数第一条指令(call指令),eip自动指向下一条指令。第一条指令的执行,致使ebp的地址值被保存在栈中,保存的目的是本程序执行完毕后,ebp还能返回现在的位置,复原现在的栈。
随着ebp地址值的压栈,esp自动向栈顶方向移动,它将永远指向栈顶。
接下来,开始构建main函数自己的栈,ebp原来指向的地址值已经被保存了,此时和esp是重叠的,用来看管main函数的栈底。
# 汇编中的寄存器
eax, ebx, ecx, edx, esi, edi, ebp, esp等都是X86汇编语言中CPU上的通用寄存器的名称,是32位的寄存器。
如果用C语言来解释,可以把这些寄存器当作变量看待。
| 汇编名称 | 寄存器类型 | 作用 |
|---|---|---|
EAX | 累加寄存器accumulator register | 加法乘法指令的缺省寄存器 |
EBX | 基址寄存器base register | 内存寻址时存放基地址 |
ECX | 程序计数器program counter | 重复REP前缀指令和LOOP指令的内定计数器 |
EDX | 用来存放整数除法产生的余数 | |
ESI | 源索引寄存器source index | 在很多字符串操作指令中, DS:ESI指向源串 |
EDI | 目标索引寄存器destination index | 在很多字符串操作指令中, ES:EDI指向目标串 |
EBP | 基址指针base pointer | 常被用作高级语言函数调用的框架指针frame pointer,存放当前线程的栈底指针 |
ESP | 堆栈指针 | 存放当前线程的栈顶指针,堆栈的顶部是地址小的区域,压入堆栈的数据越多,ESP也就越来越小。 |
EIP | 指令寄存器instrution register | 存放下一个CPU指令存放的内存地址 |
因此,在函数的起始部分经常有:
push ebp; 保存当前ebp
mov ebp, esp; EBP设为当前堆栈指针
sub esp, xxx; 预留xxx字节给函数临时变量.
2
3
# 编译过程概述
源程序是给人看的,本质上就是文本文件。需要通过编译器Compiler将源程序编译为计算机可执行的程序。
编译过程主要分为词法分析、语法分析、中间代码生成、目标代码生成四个过程。
# 词法分析
词法分析的作用是从连续的字符中识别出标识符、关键字、数字、运算符并存储为符号token流。
词法分析器Lexer,也叫扫描器Scanner,重要功能是根据对应语言的语法规则,一个字符一个字符从源程序的字符串中识别出一个个的符号token,并按序保存。
C语言的语法规则是由一个状态转换图实现的。
在词法分析阶段,词法分析器能够识别出一些符号的含义,包括关键字、数字、字符串、分隔符、运算符等,但是另外一切符号需要通过前后其他符号才能确定准确含义,仅能初步判断是一个标识符,更多详细信息在语法分析阶段完成。
# 语法分析
语法分析的作用是从词法分析识别出的token流中识别出符合对应语言语法的语句。
语法分析器Parser依据用计算机表示的语法,一个符号一个符号地识别出符合C语言语法的语句。
在语法分析器中把通过产生式产生的对应语言语法映射成一套模板,并把这套模板融汇在语法分析器的程序中。语法分析器的作用就是将词法分析器识别出的符号token一个一个地与这套模板进行匹配,匹配上这套模板中的某个语法,就可以识别出一句完整的语句,并确定这条语句的语法。
语法的计算机表示就是产生式。
语法分析器的最终输出是语法树AST,是一个二维结构。语法树已经承载了源程序的全部信息,后续的转换工作就和源程序没关系了。
# 从语法树到中间代码再到目标代码
鉴于计算机存在着多种CPU硬件平台,考虑到程序在不同CPU之间的可移植性,需要先将语法树转换成一个通用的、抽象的CPU指令,这就是中间代码最初的设计思想。然后根据具体选定的CPU,将中间代码落实到具体CPU的目标代码。
语法树是个二维结构,中间代码是准一维结构,语法树到中间代码的转换过程,本质上是将二维结构转换为准一维结构的过程。
选定具体的CPU、操作系统后,中间代码就可以转换为目标代码——汇编代码。